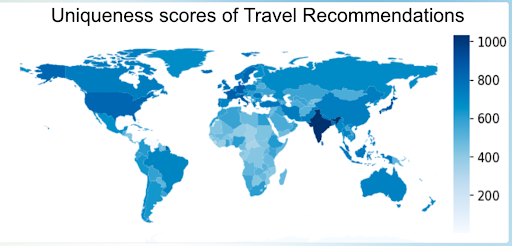
Geo-cultural biases in large language models across travel recommendations and story generation, revealing disparities in representation for poorer regions. The work also introduces STAMP, a dataset watermarking framework that enables creators to detect unauthorized use of proprietary data in language model training, promoting transparency, attribution, and responsible AI development.
Faculty: Danish Purthi
Click image to view enlarged version